Bloom Filters Para Economizar I/O
Vamos começar pelo básico :), imagine que você está construindo um sistema que precisa suportar bilhões de usuários. Agora pense em um endpoint responsável por verificar se um username já existe no banco de dados.
Mesmo com índices bem definidos, realizar uma consulta ao banco a cada tentativa de cadastro pode rapidamente se tornar um gargalo…
Em bancos de dados que utilizam Log-Structured Merge-trees (LSM-Trees) como Cassandra, os dados são escritos primeiro em memória e depois persistidos em múltiplos arquivos no disco (SSTables). Verificar se uma username existe exige procurar em várias dessas tabelas.
Se a username não estiver lá, só gastamos tempo de CPU e IOPS de disco à toa. O Bloom Filter serve como um “porteiro” extremamente rápido: ele pode dizer com 100% de certeza se um item não está no conjunto, ou dizer que ele provavelmente está.
Como Funciona
Um Bloom Filter é, em essência, um array de bits de tamanho $m$ e um conjunto de $k$ funções de hash diferentes.
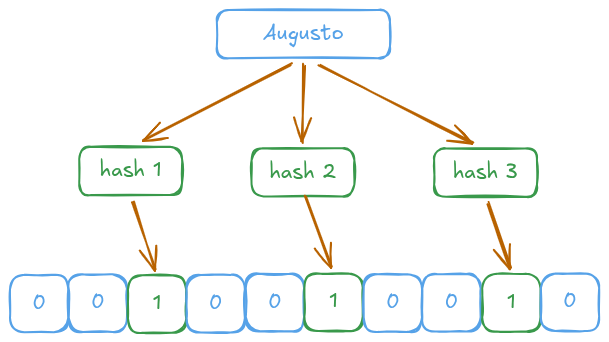
O Fluxo de Inserção
- Pegamos o elemento (ex: “augusto”).
- Passamos esse elemento por $k$ funções de hash.
- Cada função de hash gera um índice no array de bits.
- Marcamos esses índices como
1.
O Fluxo de Consulta
- Pegamos o elemento que queremos verificar.
- Passamos pelas mesmas $k$ funções de hash.
- Verificamos os bits nos índices gerados.
- Se qualquer um dos bits for 0, o elemento definitivamente não existe.
- Se todos os bits forem 1, o elemento provavelmente existe.
Representação visual dos bits sendo ativados no array após o hashing
Implementação Manual em Java
Utilizaremos a classe java.util.BitSet, que é uma das maneiras de manipular arrays de bits.
Uma técnica comum é usar o Double Hashing: a partir de dois hashes base (como o hashCode() e uma variação), podemos gerar $k$ hashes simulados.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
import java.util.BitSet;
import java.nio.charset.StandardCharsets;
import java.util.zip.CRC32;
public class BloomFilter<T> {
private final BitSet bitSet;
private final int bitSetSize;
private final int numHashFunctions;
public BloomFilter(int expectedInsertions, double falsePositiveRate) {
// Matemática para definir o tamanho ideal do BitSet (m)
// A fórmula é m = - (n * ln(p)) / (ln(2)^2)
// Onde:
// m = bitSetSize (tamanho do array de bits)
// n = expectedInsertions (número esperado de elementos)
// p = falsePositiveRate (taxa de falsos positivos desejada)
this.bitSetSize = (int) (-expectedInsertions * Math.log(falsePositiveRate) / (Math.log(2) * Math.log(2)));
// Matemática para definir o número ideal de funções de hash (k)
// A fórmula é k = (m / n) * ln(2)
// Onde:
// k = numHashFunctions (número de funções de hash)
// m = bitSetSize (já calculado)
// n = expectedInsertions
this.numHashFunctions = Math.max(1, (int) Math.round((double) bitSetSize / expectedInsertions * Math.log(2)));
this.bitSet = new BitSet(bitSetSize);
}
public void add(T element) {
long hash64 = getBaseHash(element);
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
bitSet.set(combinedHash % bitSetSize);
}
}
public boolean mightContain(T element) {
long hash64 = getBaseHash(element);
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
if (!bitSet.get(combinedHash % bitSetSize)) {
return false;
}
}
return true;
}
private long getBaseHash(T element) {
// Usamos uma combinação do hashCode padrão e CRC32 para simular um hash de 64 bits
// Converte o elemento para String.
String val = element.toString();
// Calcula o hashCode padrão da String (32 bits).
long h = val.hashCode();
// Calcula o CRC32 da String (também 32 bits).
CRC32 crc = new CRC32();
crc.update(val.getBytes(StandardCharsets.UTF_8));
// Combina os dois hashes em um único long de 64 bits:
// - 'h << 32' move o hashCode para os 32 bits mais significativos.
// - '(crc.getValue() & 0xFFFFFFFFL)' garante que o valor do CRC32 (int)
// seja tratado como um long sem extensão de sinal, ocupando os 32 bits menos significativos.
// - O operador '|' (OR bit a bit) junta os dois valores.
return (h << 32) | (crc.getValue() & 0xFFFFFFFFL);
}
public static void main(String[] args) {
BloomFilter<String> filter = new BloomFilter<>(1000, 0.01);
filter.add("user:123");
filter.add("user:456");
System.out.println(filter.mightContain("user:123")); // true
System.out.println(filter.mightContain("user:789")); // false (provavelmente)
}
}
Por que o BitSet?
O BitSet do Java é extremamente econômico. Enquanto um boolean[] consome cerca de 1 byte por posição, o BitSet usa apenas 1 bit por posição. Para um filtro de 1 milhão de bits, estamos falando de apenas ~125 KB de memória.
Falsos Positivos e Colisões
Você deve ter notado que estou usando o termo “provavelmente”. Como o “array” é finito ($m$) e o número de elementos inseridos cresce, eventualmente dois elementos diferentes podem ativar os mesmos bits.
Se você consultar “user:999” e, por coincidência, as funções de hash apontarem para bits que já foram ativados por “user:123” e “user:456”, o filtro dirá que “user:999” existe. Isso é um Falso Positivo.
No entanto, se o filtro disser que “não existe”, você pode confiar plenamente. Isso ocorre porque nunca “desativamos” um bit. Uma vez que o bit é 1, ele fica lá. Se o bit for 0, é impossível que o elemento tenha sido inserido.
Bloom Filters não permitem a remoção de itens. Se você tentar remover um item “limpando” os bits dele, poderá acidentalmente remover bits compartilhados por outros elementos, gerando Falsos Negativos (o que quebraria a garantia fundamental da estrutura).
E onde o Array de Bits fica?
Uma dúvida comum em sistemas de alta escala é: onde esse array de bits fica armazenado para receber as consultas?
Heap da JVM (RAM): Na nossa implementação Java, o
BitSetvive inteiramente na memória RAM.Persistência e Serialização: Em sistemas como o Cassandra, cada arquivo de dados no disco (SSTable) tem seu próprio Bloom Filter correspondente. Para garantir durabilidade, o filtro é serializado no disco junto com os dados. Quando o banco inicia, ele lê esses filtros e os carrega de volta para a RAM.
Aplicações no Mundo Real
- Google Chrome: Já utilizou Bloom Filters para identificar URLs maliciosas sem precisar baixar a lista completa do servidor a cada clique.
- Bancos de Dados: Cassandra os utilizam para evitar buscas em SSTables no disco.
- CDN (Content Delivery Network): Akamai usa para evitar o “caching” de itens que são acessados apenas uma vez (One-Hit Wonders).
Referências
- Artigo Original: Space/Time Trade-offs in Hash Coding with Allowable Errors (Burton H. Bloom, 1970).
- Documentação Java: Classe BitSet (Oracle).
- Google Guava: Guava BloomFilter Explained.
- Apache Cassandra: Bloom Filters in Cassandra Architecture